Introduction
The information explosion is leading to an increase in the number of documents being produced every minute. The sheer volume of documents necessitates automated ways to organize, summarize, and retrieve information. Retrieval Augmented Generative (RAG) models, a combination of retrieval and generative models, hold significant promise in addressing these challenges. In this article, we will look at the inner workings of RAG models and the associated pipeline involved in implementing them. We will cover data uploading, pre-processing, vectorizing, retrieving from a vector store, and processing queries from a large language model.
UNDERSTANDING RETRIEVAL AUGMENTED GENERATION (RAG)
At its core, RAG combines two primary components:
- Retrieval Module: This module acts as the information scout, searching a vast knowledge base (text documents, code, etc.) for content relevant to the user’s input prompt. Vector embeddings and similarity measures serve as the guiding principles for this search.
- Generation Module: This module assumes the role of the creative writer, taking the retrieved information and the input prompt as inspiration. Powerful large language models, trained on diverse datasets, craft the final text output.
When faced with a query, the retriever identifies pertinent documents from a vast corpus. These documents serve as additional context for the generator, which synthesizes a comprehensive and accurate response. As a result, RAG pipelines significantly improve search capabilities for organizations seeking rich, intuitive, and meaningful search experiences.
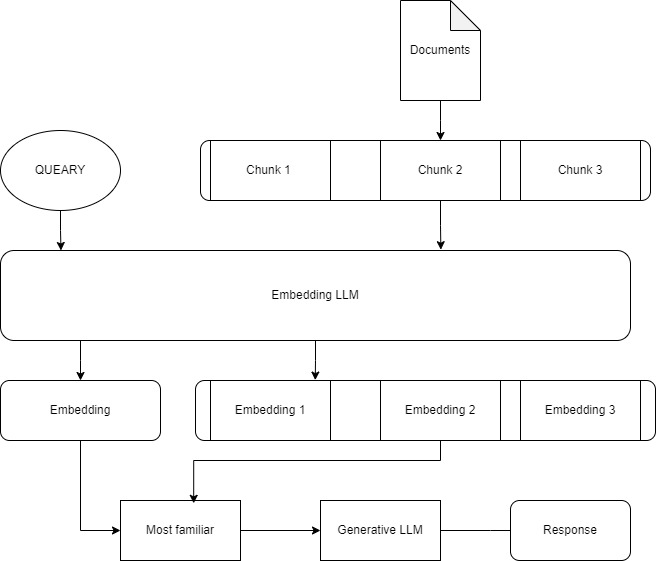
Typical RAG workflow
RAG Pipeline Steps:
- Data Uploading:
The first step in implementing a RAG model is uploading data. Depending on the use case, the data could be in the form of articles, blogs, emails, contracts, invoices, or audio transcripts. Before feeding the data to the retriever, pre-processing is done to clean, format, and structure the data appropriately.
- Pre-processing:
Pre-processing includes cleaning noise, filtering out irrelevant information, spell checking, language identification, and tokenization. Cleaning removes redundancies, duplicates, and errors introduced during the data collection process. Filtering focuses on identifying and discarding non-essential parts of the document. Spell checking is critical for ensuring the accuracy of the generated response. Language identification is performed when dealing with multilingual data sets. Tokenization refers to breaking down text into discrete units called tokens. Tokens are then converted into word embeddings, which are mathematical representations of words in a high-dimensional space.
- Vectorizing with data:
Vectorizing involves mapping each token to a point in a high-dimensional space where similar tokens lie closer to each other. Several vectorization techniques are widely adopted, including Bag-Of-Words (BOW), Term Frequency-Inverse Document Frequency (TF-IDF), Word2Vec, GloVe, BERT, and RoBERTa. BOW is a simple technique that represents each document as a bag of tokens, ignoring grammar, syntax, and word order. TF-IDF weighs terms based on their importance in the document and corpus. Word2Vec and Glove use shallow neural networks to map words to vectors. BERT and RoBERTa are transformer-based models that consider the surrounding context when vectorizing words.
- Retrieving from the Vector Store:
Once the data is vectorized, it is stored in a vector store. The vector store serves as a lookup table to identify the most relevant documents concerning a given query. Similarity search algorithms, such as cosine similarity and Euclidean distance, are commonly employed to rank documents based on their relevance score. Cosine similarity measures the angle between vectors, whereas Euclidean distance measures the straight-line distance between them.
- Processing Queries from a Large Language Model:
Queries submitted to the RAG model are processed using a large language model (LLM). The LLM determines the intent behind the query and generates an appropriate response. The LLM is initialized with weights obtained from training on a large corpus of text, enabling it to understand the context, semantics, and relationships between words.
key benefits
Applying RAG pipelines in enterprise environments brings numerous benefits:
- Richer Contextual Understanding: Generative language models trained on extensive corpora capture linguistic patterns, idioms, and cultural nuances, leading to more accurate and expressive search results.
- Improved Relevancy: The integration of dense vectors representing documents allows the algorithm to surface more precise and targeted results, surpassing traditional keyword-based approaches.
- Enhanced Explainability: Detailed explanations accompanying search results foster trust and promote adoption among users unfamiliar with AI-powered search engines.
- Scalability: Designed to handle massive volumes of structured and unstructured data, RAG pipelines gracefully scale with growing organizational needs.
Real-World Business Scenarios
Deploying RAG pipelines in businesses unlocks immense value across various domains. Some common applications include:
- Customer Support: Automatically generate personalized, accurate, and empathetic responses to customer queries based on historical tickets, FAQ pages, and community discussions.
- Research and Development: Streamline literature review processes, empower researchers to discover novel connections between publications, and maintain up-to-date knowledge graphs.
- Sales Enablement: Equip sales teams with instant access to product catalogues, competitive analyses, pricing sheets, and industry trends.
- Human Resources: Deliver employee handbooks, policy guides, job descriptions, interview tips, and compliance materials via dynamic and interactive interfaces.
- Legal Departments: Simplify contract analysis and negotiation by surfacing precedential cases, legal opinions, statutes, regulations, and treatises.
Taking the First Step
Ready to experience the power of Aerolift.AI firsthand? Visit the website to explore their features, compare licensing options, and start your free trial. Discover how Aerolift.AI can revolutionize the way you interact with documents and unlock hidden value within your data.